![]()
![]()
![]()
Reexploring SAcommunity Chatbot for Integration into Website Redevelopment Project

With AI technology moving so quickly, and Yong Kheng's team being fairly new to software development during their master’s project, there’s a lot of room to revisit and improve parts of the chatbot.
Volunteer Yong Kheng Beh, who originally built the chatbot’s backend, returned to Connecting Up on January 14, 2025, to work on refining and improving it. She’s bringing fresh insights from her internship at YourAnswer Pty Ltd (July to October 2024), along with a strong passion for learning and growth.
This blog post also doubles as a guide to how the code works and how to run it, making things easier for anyone who might pick it up in the future.
This AI chatbot improvement project has been on hold since February 25, 2025, as Yong Kheng volunteered to join the website rebuild team to support the effort. Once the website is back on track, she plans to revisit this project for integration into the new site.

Website Rebuild Team Kickoff Meeting with Head of Connecting Up, Pankaj
From left to right: Pankaj Chhalotre, Yong Kheng Beh, Stathis Avramis, Robert Quoc Huy Tran, Joe Xuanqian Zhang
Data Preprocessing
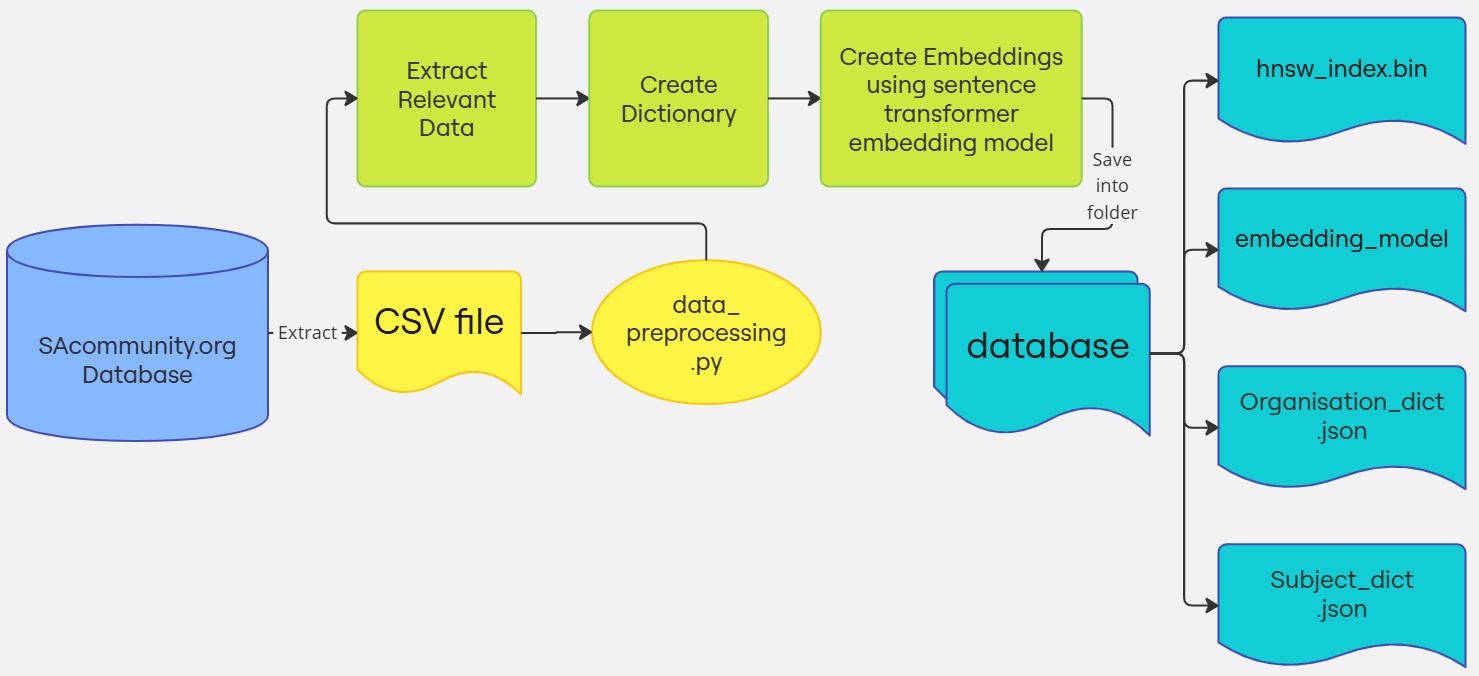
Figure 1: Flow chart of data_preprocessing.py
Yong Kheng set out to simplify the chatbot’s vector storage update process, making it possible to run everything with just a single line of code. Using the CSV she previously used for her master's project, she found a few minor data entry issues and extracted those errors and passed them along to the data entry volunteers for correction. The corrected entries, managed by the volunteer coordinator, will help ensure smoother data extraction in the future, making it easier to transition everything to the new website.
To automate the creation of the index, she wrote a Python script that can be run with the following command::
python3 data_preprocessing.py --model_name all-miniLM-L6-v2 --input_file sacommunity.csv
input_file: The CSV file containing the data to be indexed.model_name: The embedding model used to convert the data into embeddings for semantic search.
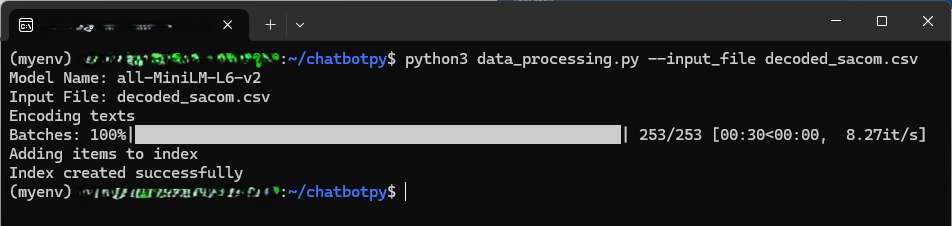
Figure 2: What it looks like when data_preprocessing.py runs
Running this script creates a folder called database, which contains the following:
- hnsw_index.bin: A HNSW index file that stores vector representations of all organization details and subjects.
- embedding_model/: A folder containing the Sentence Transformer model used for generating embeddings.
- Two JSON files:
- organisation_dict.json: A dictionary that maps organization IDs to their full details.
- subject_dict.json: A dictionary that maps each subject to all organization IDs that list it in their subject category. This helps improve the accuracy of search results.
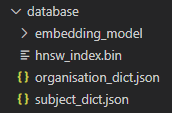
Figure 3: Files saved after running data_preprocessing.py
These files are saved locally and will be used by the chatbot program to perform semantic search.
This script serves as a prototype for data preprocessing and extraction while the website rebuild is still in progress. Future changes to the database’s content or structure may require updates to the code.
Suggestions for Improvement Once the New Website is Live
- Direct SQL Query for Data Extraction
Instead of extracting data into a CSV file and processing it separately, a more efficient approach would be to extract data directly from the database using SQL queries. However, security concerns will need to be addressed before implementing this method.
.jpg)
Figure 4: Ideal data extraction scenario
- Optimizing Index Creation for Semantic Search
At the moment, the index is built using full organization details and subject categories. A better approach might be to break the service descriptions into smaller, more meaningful chunks to boost the accuracy of semantic search.
However, since the dataset includes over 15,000 organizations—and each one describes their services a bit differently—this chunking could eat up more memory and slow down search performance. So it's important to find the right balance between search accuracy, speed, and memory usage.
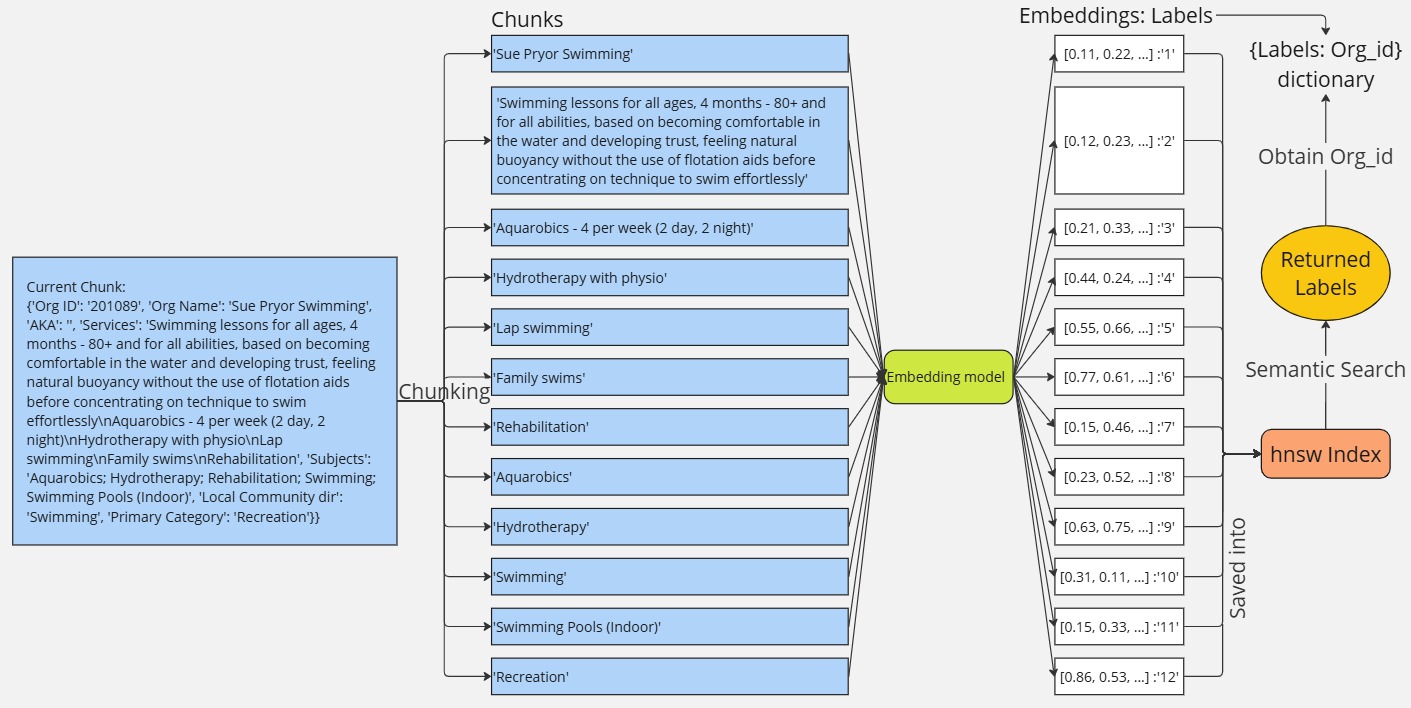
Figure 5: Example of ideal chunking and indexing
- Improving Location-Based Search
To make location-based searches more useful, adding a dedicated index for location info could really help people find nearby services more easily. Previously, the chatbot used the free version of the Nominatim Geocoder to fetch nearby locations—but it only allows one request per second, which can seriously slow things down.
Since cost is always a factor for nonprofits, here are a few options to consider:
- Paying for the Google Maps API.
- Hosting a local version of Nominatim (though this needs a lot of computing power).
- Building a smarter location search tool that can handle typos or unclear addresses.
The code for this preprocessing step, written by Yong Kheng, is available in the attached file: data_preprocssing.pdf.
Chatbot Program Semantic Search
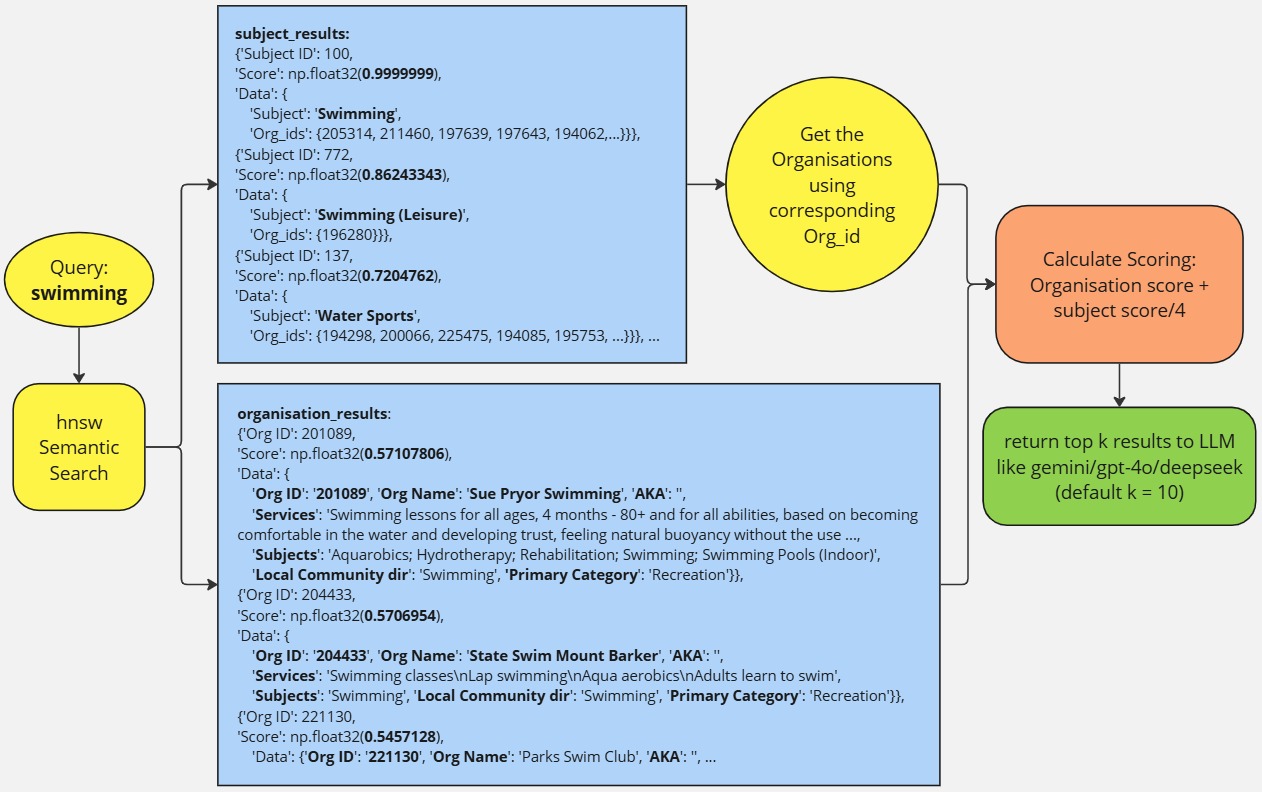
Once the data is ready, the next step is running chatbot.py. This program searches the index semantically, pulls out the most relevant data from the dictionaries, scores and ranks them, and then returns the top 10 results. These results are sent to the Large Language Model (LLM), which processes them using prompt engineering to generate a useful response.
The index can be created using tools like hnswlib, FAISS, ScaNN, or Usearch. They all do similar things, but FAISS, ScaNN, and Usearch offer more flexibility, while hnswlib is simpler and easier to set up.
As for the LLM, the choice depends on the organization’s needs and preferences. Yong Kheng is currently using Gemini, since it has a free trial. However, it’s important to know that any data sent to the free version may be used for training, so private or sensitive information should be avoided
