![]()
![]()
![]()
SAcommunity.org Chatbot Project

Image: Adelaide University Industry Project presentation (L-R): Clover Xinyue Luo, Yong Kheng Beh, Violet Zewei You, and Jamie Jiemin Zhang
Yong Kheng Beh provided an outline of the SAcommunity Chatbot project below:
This project presents an AI chatbot powered by a Large Language Model (LLM) for SAcommunity.org, designed to complement the existing search engine. We successfully developed a chatbot that enables users to have human-like conversations, remembers the conversation, understand their needs, search the SAcommunity database, and deliver relevant information back to them. By using the chatbot, users can easily obtain the information they need, while "difficult-to-find" organisations or communities have better opportunities to be discovered, creating a two-way benefit.
1 Introduction
SAcommunity.org provides valuable information about South Australian communities, covering services in health, welfare, housing, education, community activities, recreation, and more. While the search engine on the website is functional, there are opportunities for enhancement to make the user experience even better.
Some areas for improvement include:
- Occasionally, search results may include some irrelevant entries due to the presence of similar words in various listings.
- Precision in spelling is necessary; for example, “seniors” and “senior” produce different outcomes.
- Searches for terms with similar meanings, such as “drug abuse” and “drug addiction,” currently yield distinct results.
- Filtering is currently limited to council areas, which might pose a challenge for those unfamiliar with the specific council boundaries.
This project aims to implement an AI chatbot that will address these opportunities for improvement, enhancing the search experience without altering the existing website structure.
2 Project Aims
This chatbot project aims to complement the search feature of the website through the following functions:
- The chatbot shall appear as a pop-up on the SAcommunity.org main page, without interrupting the users' existing experience with the website.
- The chatbot shall enable users to inquire about the services they are interested in as well as the location of these services.
- The chatbot shall leverage LLM to have normal conversations with users and understand their intent, even vague ones.
- The chatbot shall be able to fetch up-to-date information from the website database according to users' queries using retrieval-augmented generation (RAG).
- The chatbot shall be able to return a list of relevant organisations along with links to the webpage for users to get more information.
- The chatbot shall retain the conversation history while the webpage stays open to better understand user intent. However, it will not retain any user information, and the memory will be cleared once the webpage is closed by the user.
- The chatbot shall be transferable to other websites if the client intends to move to a newer website or also implement the technology on other company websites, with some minor changes.
3 Approach
3.1 Software Architecture
The following figure (Figure 1) is the most recent architecture of our chatbot.
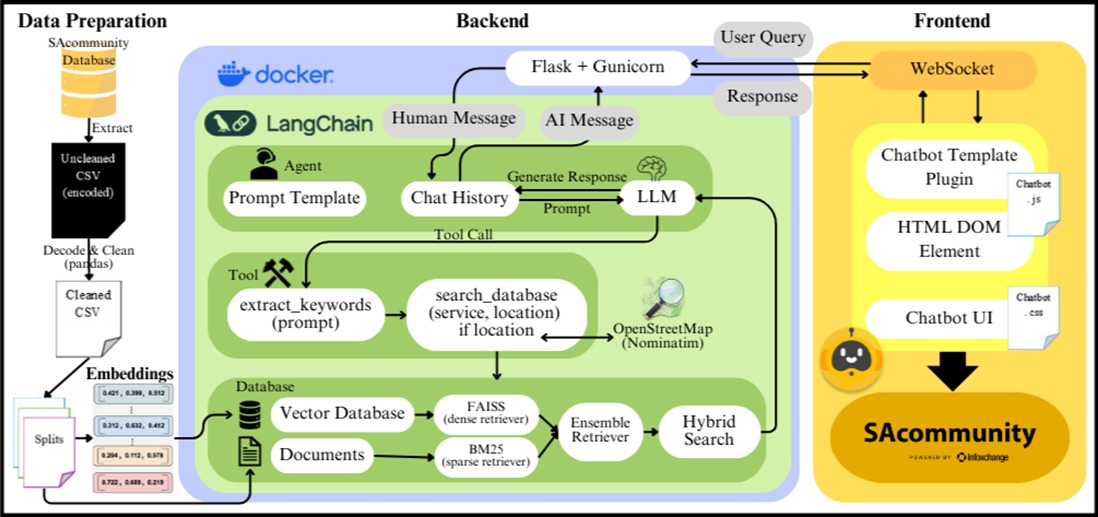 Figure 1. Architecture of SACommunity.org Chatbot
Figure 1. Architecture of SACommunity.org Chatbot
From the frontend, users interact with the chatbot by entering their query. The query is then sent to the backend via JavaScript WebSocket. In the backend, Flask receives the query and passes it to the Agent in LangChain. The query is stored as "HumanMessage" in the Agent's chat history. The Agent, given specific instructions by the prompt template, interprets the query, now a prompt, by using the LLM to decide whether to generate a response or proceed with a tool call. If a tool call is needed, the tool extract_keywords() is called to extract keywords, which are then passed into the search_database() function. The search results are returned to the agent, which uses the LLM again to analyse and generate a response. The generated response is saved as "AIMessage" in the chat history and returned to the frontend. An in-depth explanation of the functionality of each component in this architecture is explained next.
3.2 Software and tools
3.2.1 Frontend
PHP, CSS, and JavaScript are used to build the chatbot's frontend user interface. Additionally, JavaScript establishes connections to the backend.
3.2.2 Backend
LangChain
The backend of this project is made possible by importing LangChain libraries. LangChain is an open-source toolkit that enables developers to easily construct LLM-powered apps (LangChain 2024). It offers two coding language options: Python and JavaScript. Python was chosen because YongKheng Beh, the main developer of the backend, is only proficient in Python. LangChain can integrate with various LLM providers such as Cohere, Google, MistralAI, OpenAI, and more. Additionally, LangChain has many components; the following components were used for the development of the SAcommunity.org chatbot.
Agent: An agent can use LLM as a reasoning engine to determine what action to take, which tools to use, and retain chat history.
- Without using an agent, the chatbot would fail to have a normal conversation, as it would always reply with a search result. This issue occurred in our earlier chatbot implementation using naïve retrieval-augmented generation (RAG), where the chatbot would respond to "Hello" with "I cannot find any relevant result".
LLM Chat Models: The main component of the chatbot. When given the correct instructions, the LLM can perform specific tasks such as RAG. For this project, the temperature is set to 0 to achieve more consistent results. Setting the temperature to 1 would make the LLM more creative and prone to hallucinations.
- Initially, we used Gemini by Google because it offers a free trial for development.
- Due to concerns about data privacy and ownership from our client, we explored local LLM models such as Ollama, which enables the download and usage of local LLMs like Meta Llama3 or Microsoft Phi 3. However, these models require a GPU and significant disc space (at least 5GB) to run efficiently.
- Later, with the implementation of an agent, we switched to Cohere (a Canadian LLM company), which also had a free trial but only up to 1,000 API calls per month. Gemini by Google and Ollama do not support the implementation of an agent.
- Finally, after successfully deploying the chatbot into the development environment, our client suggested switching to OpenAI (supports agent implementation), as they were already using it for another project and had an existing API key.
Embedding Models: Embedding models convert the documents into numeric representations (vectors) that are stored in a vector store.
- Initially, we used Google's GoogleGenerativeAIEmbeddings to embed the documents. However, due to concerns about data privacy, ownership, and security, we explored alternatives such as local embedding features.
- Hugging Face provides numerous free open-source local embedding models. We downloaded and tested a few, but they did not perform as well as GoogleGenerativeAIEmbeddings in terms of similarity search for semantic meanings.
- We ultimately chose the embedding feature by GPT4All, which downloads the embedding model (SBERT by default) locally and converts the documents to embeddings on the local machine. SBERT surprisingly improved the similarity search results, despite creating smaller dimension embeddings compared to GoogleGenerativeAIEmbeddings.
- Sentence-BERT (SBERT), a modification of the pretrained BERT model, proved to have improved performance in similarity searches while requiring significantly less computational effort.
- FAISS (Facebook AI Similarity Search) functions as both a vectorstore and a retriever. It uses RAM for efficient similarity search but also allows the index to be saved on disk. Saving onto disk enables the index to be quickly loaded into RAM when needed, rather than recreating the data structure from scratch, which saves time. Using FAISS, similarity search can be performed to find documents with semantic meanings similar to the search query.
- After testing with a few different queries using FAISS, we noticed that the accuracy was still not up to our expectations. Therefore, we explored alternative vectorstore such as Chroma due to its additional features compared to FAISS. However, the search accuracy did not improve, and the vector database created via Chroma was taking up more disc space than FAISS, so we reverted to using FAISS.
- Both Chroma and FAISS uses semantic search which they will often miss organisations that provide multiple services. Therefore, we introduced another retriever, Okapi BM25.
- Okapi BM25 is a sparse retriever, in contrast to FAISS, which is a dense retriever. It searches using a bag-of-words method where more matches result in a better score, longer documents result in a lower score, and the frequency and position of the keyword also influence the score.
- We ultimately used an ensemble retriever, which combines FAISS and BM25, to improve accuracy of the search results.
Tools: These can also be understood as functions, which the agent uses to perform specific tasks. LangChain provides multiple predefined tools, such as Wikipedia Search, YouTube Search, and OpenWeatherMap. For this chatbot, we defined our own tools: extract_keywords() and search_database().
Other software or tools in the backend in addition to LangChain
Nominatim: Uses OpenStreetMap data to find locations on Earth by name and address (geocoding). This allows for filtering in the chatbot's search logic, resulting in more accurate search results.
Flask + Gunicorn: To establish a persistent connection with the frontend of our chatbot application, we have implemented the Flask framework along with the Flask-SocketIO library. To deploy Flask application to the web, we utilize Gunicorn. Gunicorn acts as an intermediary server that communicates between the web server and the web application.
Docker: Enables the deployment of the chatbot app across various environments, independent of their technology versions. Upgrading the website's technology may cause unwanted crashes, requiring additional fixes. Therefore, it is important to have the chatbot application containerized and separated from the website environment.
3.2.3 Data Preparation
Jupyter Notebook, pandas: Data extraction was done by the web developer at Connecting Up. Data decoding, analysis, and cleaning were performed using Jupyter Notebook, primarily utilising the pandas library.
3.3 Main Development Phase
The development of the chatbot consists of five stages: simple chatbot (without knowledge base), data analysis and preparation, naïve RAG chatbot, agentic RAG chatbot with optimization of search accuracy, and deployment.
3.3.1 Simple Chatbot (without knowledge base)
At the project's onset, our priority was to develop a chatbot without any knowledge base to establish a functional framework for the LLM chatbot. For the frontend, Jiemin Zhang searched for a suitable chatbot template that could later be modified to align with the SAcommunity.org theme. In the backend, Yongkheng Beh implemented the LLM API call and interaction using Python with LangChain. Zewei You then connected the backend and frontend using Flask, resulting in the creation of a simple LLM-powered chatbot.
3.3.2 Data Analysis and Preparation
We then analysed and cleaned the data provided by the web development team at Connecting Up. Utilising the Python pandas library, we imported the CSV to visualize the data and proceeded with decoding and cleaning. When data entry issues were identified, we collaborated with Connecting Up staff to address these inappropriate entries. Ensuring proper data entry from the beginning will facilitate smoother data extraction and cleaning processes in the future.
3.3.3 Naïve RAG Chatbot
The next step was to implement Naïve Retrieval-Augmented Generation (RAG) (Figure 2) with the prepared data. This process involved indexing, which includes splitting the documents, embedding them, and storing them in a vector store. LangChain's document loader, by default, simultaneously loads the CSV file and splits it into separate documents according to rows. Document embedding was accomplished using GoogleGenerativeAIEmbeddings, and the embeddings were stored locally using the FAISS vector store, which also serves as a retriever. The user query is input into the retriever to obtain the relevant documents. Using LangChain, the user query, together with the returned documents, is pipelined into a prompt template, and the entire prompt is given to the LLM for processing, producing output in the specified format.
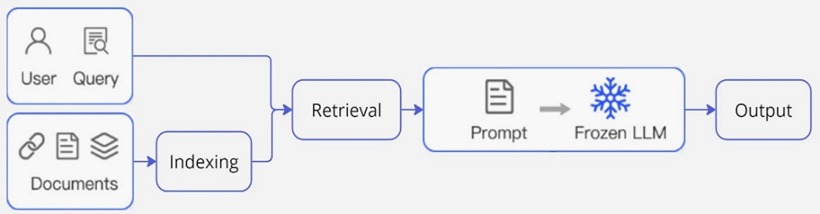 Figure 2. Naïve RAG Pipeline (Gao et al. 2024)
Figure 2. Naïve RAG Pipeline (Gao et al. 2024)
Through Naïve RAG, the chatbot can interpret user queries regardless of spelling and retrieve the relevant information, providing links back to the users. Implementing Naïve RAG was Yongkheng responsibility, and it served as a great introductory project to explore LangChain's functionality.
3.3.4 Agentic RAG Chatbot + Optimisation of Search Accuracy
The implementation of Naïve RAG represents a significant breakthrough for this project; however, it has several major flaws. It cannot engage in normal conversations, its search accuracy remains low, it cannot record chat history, and it struggles to understand vague queries and convert them into more effective search terms. These challenges were eventually solved with our subsequent discovery and implementation of Agentic RAG, on our journey to optimize search accuracy.
To enhance search accuracy, Zewei You, proposed the idea of extracting keywords from user input to conduct advanced searches. Yongkheng Beh was tasked with implementing this idea using LangChain. Upon further exploration of LangChain's features, Yongkheng Beh discovered their "tools" and "agent" functionalities. By utilizing "tools", we can extract keywords from the query, while the "agent" feature enables tool calls, chat history and normal conversation.
In the agentic RAG implementation, we integrated two tools. The 'extract_keywords()' is designed to extract two key pieces of information from the conversation: 'service' and 'location'. These extracted keywords are then passed into our second tool, 'search_database()', to execute the search logic as described in Figure 3. However, we encountered issues regarding the detection of correct user-provided addresses and their matching in the similarity search. Towards the end of this stage, Zewei You discovered the Nominatim library, which utilizes OpenStreetMap data to obtain accurate locations. In the 'search_database()' function, if the extracted keywords contain location information, the 'suburb' and 'council' are obtained from the OpenStreetMap library, and a filter is applied to the retriever.
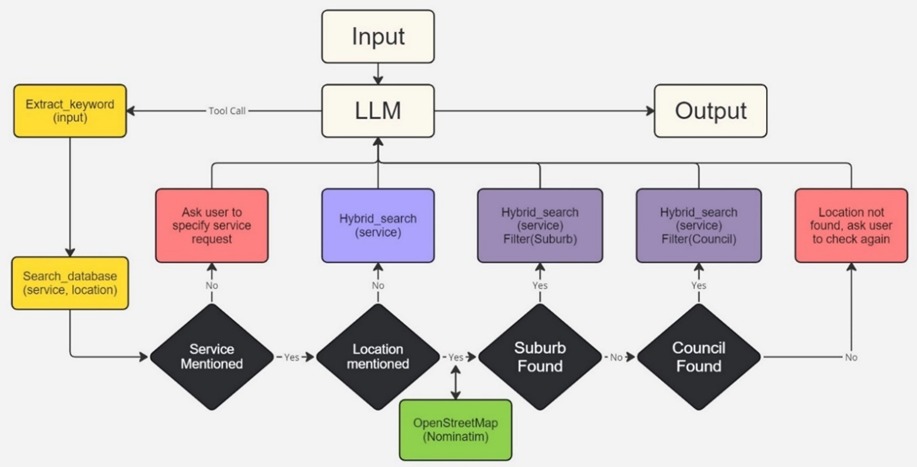 Figure 3. Search logic of chatbot
Figure 3. Search logic of chatbot
However, just applying the search logic did not significantly improve the search results, as the retriever was not retrieving enough related documents. It had to be coupled with an Ensemble Retriever. We eventually opted for an ensemble retriever consisting of FAISS and BM25, which notably increased the accuracy of similarity searches. Coincidentally, transitioning from GoogleGenerativeAIEmbeddings to GPT4All's default local embedding feature, SBERT, also led to improved search results.
Data quality is another important factor in improving search accuracy. The presence of irrelevant information in each split document makes it more challenging to retrieve accurate information. Therefore, at this stage, we discarded even more irrelevant data, retaining only vital information such as the services provided by the organisation and the location. Additionally, including "Suburb" and "Council" as metadata for each split enables search filtering. An additional benefit of removing redundant information is cost savings, as it reduces the token count sent to the LLM.
After successfully implementing agentic RAG with chat history, we encountered another issue. Flask's connection is not persistent, preventing the session from being maintained and the history from being stored due to the constant establishment of new connections. To address this, Zewei You sought a solution and implemented Flask-SocketIO, which provides a persistent connection.
As a result, the chatbot is now capable of having normal conversations, retaining chat history, extracting user queries, understanding vague queries, and improving search results. During this stage, Yongkheng Beh implemented the agentic RAG with chat history, defined the two tools and ensemble retriever, while collaborated with Zewei You to further enhance the search logic and data quality.
3.3.5 Deployment
With the success of the agentic RAG chatbot, it was time to deploy it. To deploy the chatbot as a pop-up on the existing webpage, a small part of the website's PHP code was modified. The chatbot's appearance was styled using CSS to match the theme of SAcommunity.org which was done by Xinyue Luo and Jiemin Zhang. The main part of the frontend is powered by JavaScript. Users can interact with the chatbot by expanding or minimizing it, entering queries, and receiving responses. WebSocket also implemented in the JavaScript to establish a connection to the chatbot’s backend via Flask-SocketIO. Additionally, a function is added to the JavaScript to detect bots and avoid unwanted spam directed at the chatbot.
The deployment of the frontend went smoothly, but we encountered a problem with deploying the backend: the Ubuntu version was only 16.04, and Python was only version 2.7, whereas the minimum requirement for the chatbot to run is Python 3.10. Initially, Zewei You considered using PyInstaller to create an executable file for deployment, as the produced executable file does not require Python to run on computers that do not have Python installed. However, the outdated Ubuntu version prevented the executable file from running. To avoid disrupting or crashing the website, we decided to use Docker to containerize the chatbot backend and deploy it.
For the application to interact with the webserver when creating a Docker container for publication, we then integrated Gunicorn. However, we were still facing issues with the connection due to some permission issues. With some help from the web development team at Connecting Up to allow permissions from AWS and making some minor changes in the connection codes of Docker and chatbot backend python code, the chatbot is finally up and running in the development environment.
4 Results
4.1 Achievements
For the first half of our project, we achieved our two main goals:
- Developed a simple conversational AI chatbot capable of processing prompts and delivering coherent responses without incorporating external knowledge bases.
- Analysed, cleaned, and prepared the database to create a knowledge base for the Retrieval-Augmented Generation (RAG) of the chatbot.
Additionally, we went beyond these goals and implemented a Naïve RAG chatbot.
Towards the end of the project, we successfully deployed the Agentic RAG chatbot to the development environment of the SAcommunity website. The current SAcommunity chatbot is now capable of:
- Providing better search accuracy, meaning the chatbot fetches more relevant results.
- Returning a list of relevant organisations with links.
- Understanding vague requests and still giving relevant information.
- Correcting misspellings.
- Retaining chat history without mixing it up.
- Obtaining accurate locations using Nominatim.
- Having a frontend theme that matches the SAcommunity website.
- Implementing bot detection to prevent spam.
- Being transferable to other websites due to its Dockerized implementation

Figure 4: Chatbot when opening SAcommunity.org main page

Figure 5: Chatbot expanded clicked on the chatbot icon.

Figure 6: Chatbot response when queried.
5 Conclusion
5.1 Summary
After weeks of effort, we managed to create a product that fulfills the project's aim: an interactive AI chatbot capable of complementing the website's search engine by understanding users' needs and providing relevant information. This exceeded our expectations, especially considering none of us had prior knowledge of large language models or experience in creating such an application.
We gained extensive knowledge from this project, covering backend components such as LangChain and Docker, as well as connection technologies like Flask, Flask-SocketIO, Gunicorn, and WebSocket, and frontend elements including PHP, CSS, HTML, and JavaScript. Most of this knowledge was acquired through self-teaching via online tutorials, documentation reading, and collaborative learning among team members. Additionally, we appreciate Connecting Up's support and positive feedback throughout the project. It was truly a team effort.
5.2 Future Extensions
There are exciting opportunities for further development of this chatbot, such as establishing a feedback system and a database to store chat history without any sensitive information. The client envisions implementing simple "thumbs up" and "thumbs down" buttons at the end of conversations to easily identify user feedback. Additionally, with the successful integration of Docker and Gunicorn, we suggest refining this setup and incorporating Nginx for optimal performance.
Although these features would greatly enhance the chatbot, there is a consideration regarding memory capacity. Our client currently has 1GB of cloud memory, with the running chatbot Docker container utilizing over 50% of this capacity. Combined with the website's default memory usage, only about 5% of memory remains unused. The client will decide whether to increase the memory to support these additional features for the chatbot in the future.
5.3 Disclaimer
For those interested in the underlying code of the chatbot, PDF copy of the Python code can be obtained from the link below. However, due to the continuous improvements of LangChain as a relatively new open-source toolkit, some of the libraries may become redundant in the future, while others may be added (e.g., Ollama previously did not support tool calls, but on 24th July 2024, Ollama launched its own tool call feature). Therefore, the code should be used as a guide and will need to be updated with the latest features.
